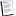
just in case i dinnt type all of this......
A hash function (or hash algorithm) is a way of creating a small digital "fingerprint" from any kind of data. The function chops and mixes (i.e., substitutes or transposes) the data to create the fingerprint, often called a hash value. The hash value is commonly represented as a short string of random-looking letters and numbers (Binary data written in hexadecimal notation). A good hash function is one that yields few hash collisions in expected input domains. In hash tables and data processing, collisions inhibit the distinguishing of data, making records more costly to find.
A typical hash function at workContents [hide]
1 Properties of hash function
2 Applications of hash function
2.1 Cryptography
2.2 Hash tables
2.3 Error correction
2.4 Audio identification
2.5 Rabin-Karp string search algorithm
3 Origins of the term
4 See also
5 References
6 External links
[edit]
Properties of hash function
A fundamental property of all hash functions is that if two hashes (according to the same function) are different, then the two inputs are different in some way. This property is a consequence of hash functions being deterministic. On the other hand, a hash function is not injective, i.e. the equality of two hash values ideally strongly suggests, but does not guarantee, the equality of the two inputs. If a hash value is calculated for a piece of data, and then one bit of that data is changed, a hash function with strong mixing property usually produces a completely different hash value.
Typical hash functions have an infinite domain, such as byte strings of arbitrary length, and a finite range, such as bit sequences of some fixed length. In certain cases, hash functions can be designed with one-to-one mapping between identically sized domain and range. Hash functions that are one-to-one are also called permutations. Reversibility is achieved by using a series of reversible "mixing" operations on the function input.
[edit]
Applications of hash function
Because of the variety of applications for hash functions (details below), they are often tailored to the application. For example, cryptographic hash functions assume the existence of an adversary who can deliberately try to find inputs with the same hash value. A well designed cryptographic hash function is a "one-way" operation: there is no practical way to calculate a particular data input that will result in a desired hash value, so it is also very difficult to forge. Functions intended for cryptographic hashing, such as MD5, are commonly used as stock hash functions.
Functions for error detection and correction focus on distinguishing cases in which data has been disturbed by random processes. When hash functions are used for checksums, the relatively small hash value can be used to verify that a data file of any size has not been altered.
[edit]
Cryptography
Main article: cryptographic hash function
A typical cryptographic one-way function is not one-to-one and makes an effective hash function; a typical cryptographic trapdoor function is one-to-one and makes an effective randomization function.
[edit]
Hash tables
Main article: Hash table
Hash tables, a major application for hash functions, enable fast lookup of a data record given its key. (Note: Keys are not usually secret as in cryptography, but both are used to "unlock" or access information.) For example, keys in an English dictionary would be English words, and their associated records would contain definitions. In this case, the hash function must map alphabetic strings to indexes for the hash table's internal array.
The generally impossible/impractical ideal for a hash table's hash function is to map each key to a unique index (see perfect hashing), because this guarantees access to each data record in the first probe into the table.
Hash functions that are truly random with uniform output (including most cryptographic hash functions) are good in that, on average, only one or two probes will be needed (depending on the load factor). Perhaps as important is that excessive collision rates with random hash functions are highly improbable—if not computationally infeasible for an adversary. However, a small, predictable number of collisions is virtually inevitable (see birthday paradox).
In many cases, a heuristic hash function can yield many fewer collisions than a random hash function. Heuristic functions take advantage of regularities in likely sets of keys. For example, one could design a heuristic hash function such that file names such as FILE0000.CHK, FILE0001.CHK, FILE0002.CHK, etc. map to successive indices of the table, meaning that such sequences will not collide. Beating a random hash function on "good" sets of keys usually means performing much worse on "bad" sets of keys, which can arise naturally—not just through attacks. Bad performance of a hash table's hash function means that lookup can degrade to a costly linear search.
Aside from minimizing collisions, the hash function for a hash table should also be fast relative to the cost of retrieving a record in the table, as the goal of minimizing collisions is minimizing the time needed to retrieve a desired record. Consequently, the optimal balance of performance characteristics depends on the application.
One of the most respected hash functions for use in typical hash tables is Bob Jenkins' LOOKUP2 hash function, published in an article in Dr. Dobb's Journal. The hash function performs well as long as there is no adversary, for it is trivially reversible and useless as a cryptographic hash function.
[edit]
Error correction
Main article: Error correction and detection
Using a hash function to detect errors in transmission is straightforward. The hash function is computed for the data at the sender, and the value of this hash is sent with the data. The hash function is performed again at the receiving end, and if the hash values do not match, an error has occurred at some point during the transmission. This is called a redundancy check.
For error correction, a distribution of likely perturbations is assumed at least approximately. Perturbations to a string are then classified into large (improbable) and small (probable) errors. The second criterion is then restated so that if we are given H(x) and x+s, then we can compute x efficiently if s is small. Such hash functions are known as error correction codes. Important sub-class of these correction codes are cyclic redundancy checks and Reed-Solomon codes.
[edit]
Audio identification
For audio identification such as finding out whether an MP3 file matches one of a list of known items, one could use a conventional hash function such as MD5, but this would be very sensitive to highly likely perturbations such as time-shifting, CD read errors, different compression algorithms or implementations or changes in volume. Using something like MD5 is useful as a first pass to find exactly identical files, but another more advanced algorithm is required to find all items that would nonetheless be interpreted as identical to a human listener. Though they are not common[citation needed], hashing algorithms do exist that are robust to these minor differences. Most of the algorithms available are not extremely robust, but some are so robust that they can identify music played on loud-speakers in a noisy room.[citation needed] One example of this in practical use is the service Shazam. Customers call a number and place their telephone near a speaker. The service then analyses the music, and compares it to known hash values in its database. The name of the music is sent to the user (for a charge!). An open source alternative to this service is MusicBrainz which creates a fingerprint for an audio file and matches it to its online community driven database.
[edit]
Rabin-Karp string search algorithm
Rabin-Karp string search algorithm is a relatively fast string searching algorithm that works in O(n) time on average. It is based on the use of hashing to compare strings.
[edit]
Origins of the term
The term "hash" apparently comes by way of analogy with its standard meaning in the physical world, to "chop and mix." Knuth notes that Hans Peter Luhn of IBM appears to have been the first to use the concept, in a memo dated January 1953; the term hash came into use some ten years later.
In the SHA-1 algorithm, for example, the domain is "flattened" and "chopped" into "words" which are then "mixed" with one another using carefully chosen mathematical functions. The range ("hash value") is made to be a definite size, 160 bits (which may be either smaller or larger than the domain), through the use of modular division.  |